What it is
Reasonable UX is a Playwright-based audit agent. It walks a site through ten steps of screenshot → reasoning → action, scores the UX across heuristics, re-reads the findings through three to five personas inferred from the site itself, and stitches the pages together into a single executive summary. Output is a PDF.
The thing I care about is the reasoning layer. Most agent projects end up shaped like this: one model, one prompt, everything runs at whatever tier you paid for. That's expensive on a long-horizon task, and the ceiling on quality is whatever the single model happens to be good at. Reasonable UX is tiered by reasoning depth instead — cheap models do the cheap work, expensive models are consulted only when judgment is actually needed.
A single Opus-only run across a multi-page site cost ~$8. That's not viable for iterative calibration.
Architecture
URL input
↓
Scout [Haiku 4.5] preflight — bot-block check, interest 1–5
↓ interest ≥ 3?
Executor [Sonnet 4.6] 10-step screenshot → reasoning → Playwright action loop
↓ escalate?
Advisor [Opus 4.6] judgment-only — beta advisor_20260301 tool
executor decides when to escalate; ~8 calls/run
↓
Synthesis [Haiku 4.5] multi-page exec summary
↓
PDF report Why not Opus everywhere?
A full Opus run cost ~$8. The architecture question was whether the advisor escalation pattern justified its premium. The eval found it didn't: v3_8step (no advisor) posted 2W/1L vs baseline at $0.70/run. v2_advisor cost $1.83 for a 1W/2L record. The cheaper architecture won.
Why strip image history?
Screenshot bloat is the first cost wall on a multi-step agent loop. Stripping prior images from message history after each step — keeping text reasoning, discarding the visuals — was the highest-leverage cost change in the project. Wired in the first commit, not added under budget pressure. Without it, layering the advisor on top wouldn't pencil out.
Why nav:Label instead of CSS selectors?
The prompt instructs Claude to emit "target": "nav:Pricing" for navigation clicks. Dispatch translates that to get_by_role('link', name='Pricing'). Brittle selectors break when classes change; a semantic handle doesn't. This is the kind of thing the executor wouldn't arrive at on its own — it required a deliberate convention imposed at prompt-design time.
Eval harness
The advisor variant posted 1W/2L against the no-advisor baseline. The cheapest configuration won two of three sites. I needed a way to quantify that before acting on it — so I built a separate eval harness.
- Pre-registered rubric locked before any judge calls: 4 dimensions (overall verdict, specificity, actionability, coverage)
- 2-run pilot for calibration, locked before the full sweep
- 17 Opus-as-judge pairwise comparisons, randomized A/B label order, $0.58 total
- Nav drift regression detection:
_nav_drift_check()fires on every eval run, flags CSS-selector violations automatically
| Variant | Cost | tok/step | Overall verdict |
|---|---|---|---|
| v1_baseline | $1.32 | 9,430 | champion |
| v3_8step | $0.70 | 6,753 | 2W / 1L — cheapest winner |
| v2_advisor | $1.83 | 12,703 | 1W / 2L |
| v4_8step_adv | $1.21 | 10,539 | 2W / 1L |
Finding: the advisor tool added 38–160% cost overhead while losing the overall verdict comparison 1W/2L. v3_8step matched its quality record at 47% of the cost.
Live artifacts
Audited: Stripe Linear Glossier Figma
Reports available on request. Composite scores ranged 2.00–3.26 across sites and variants.
Report output
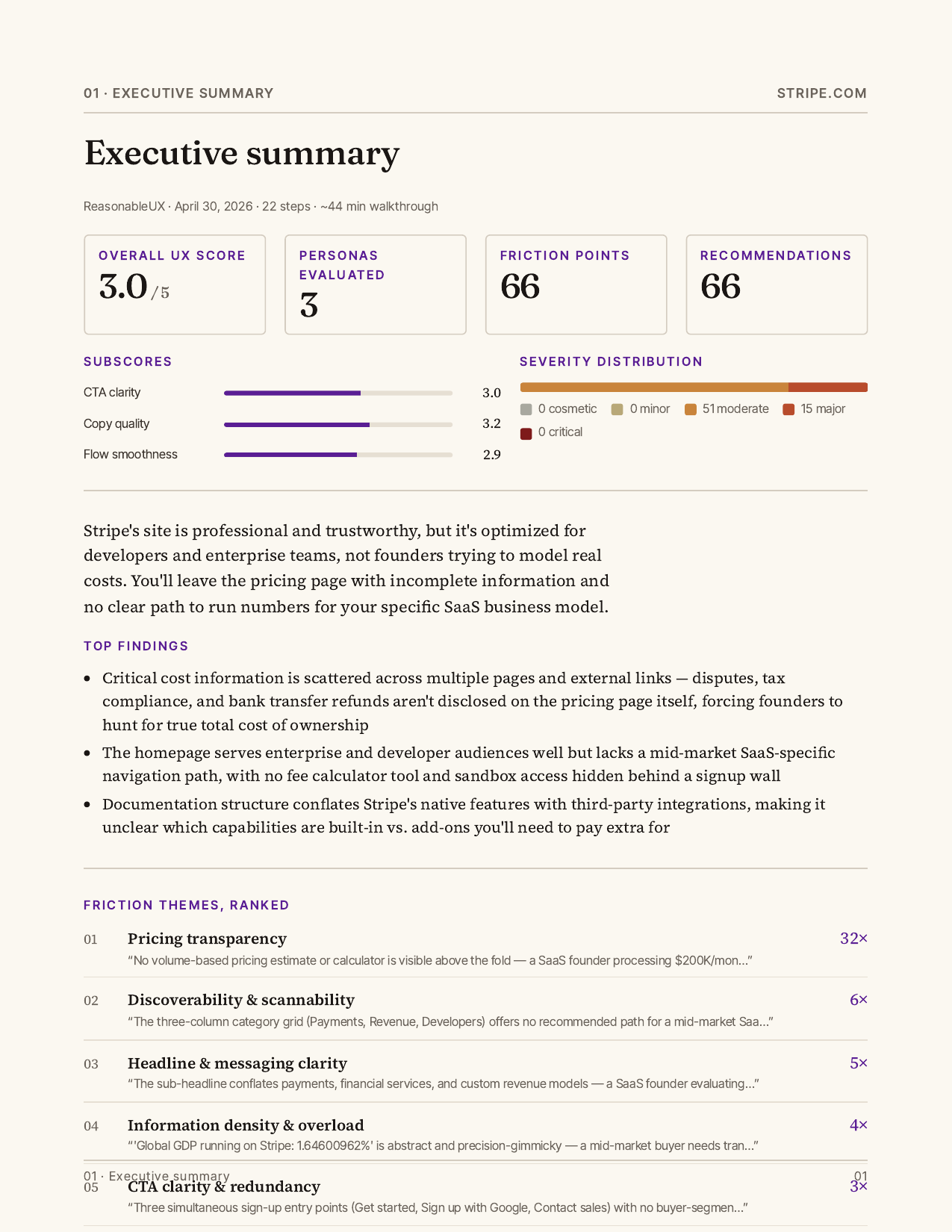
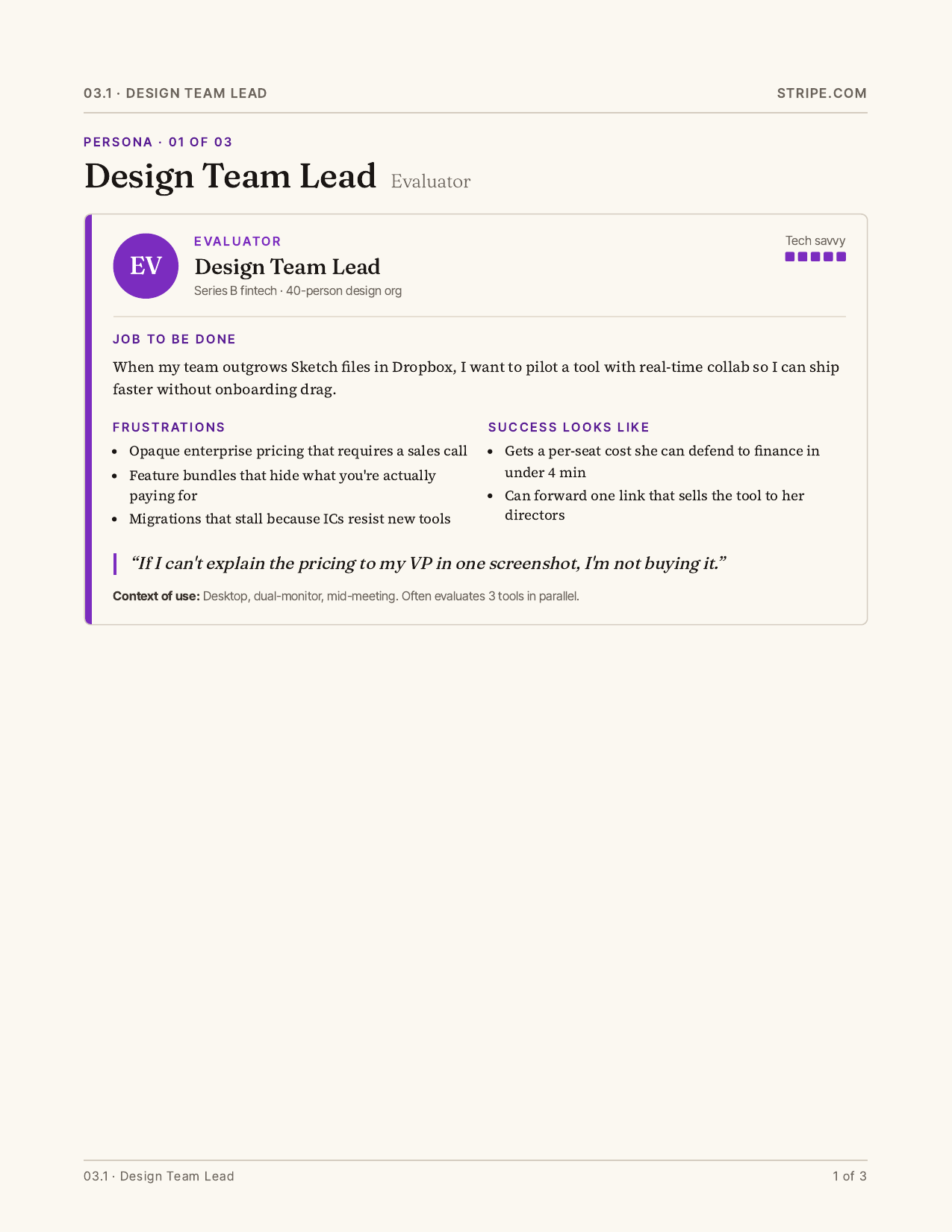
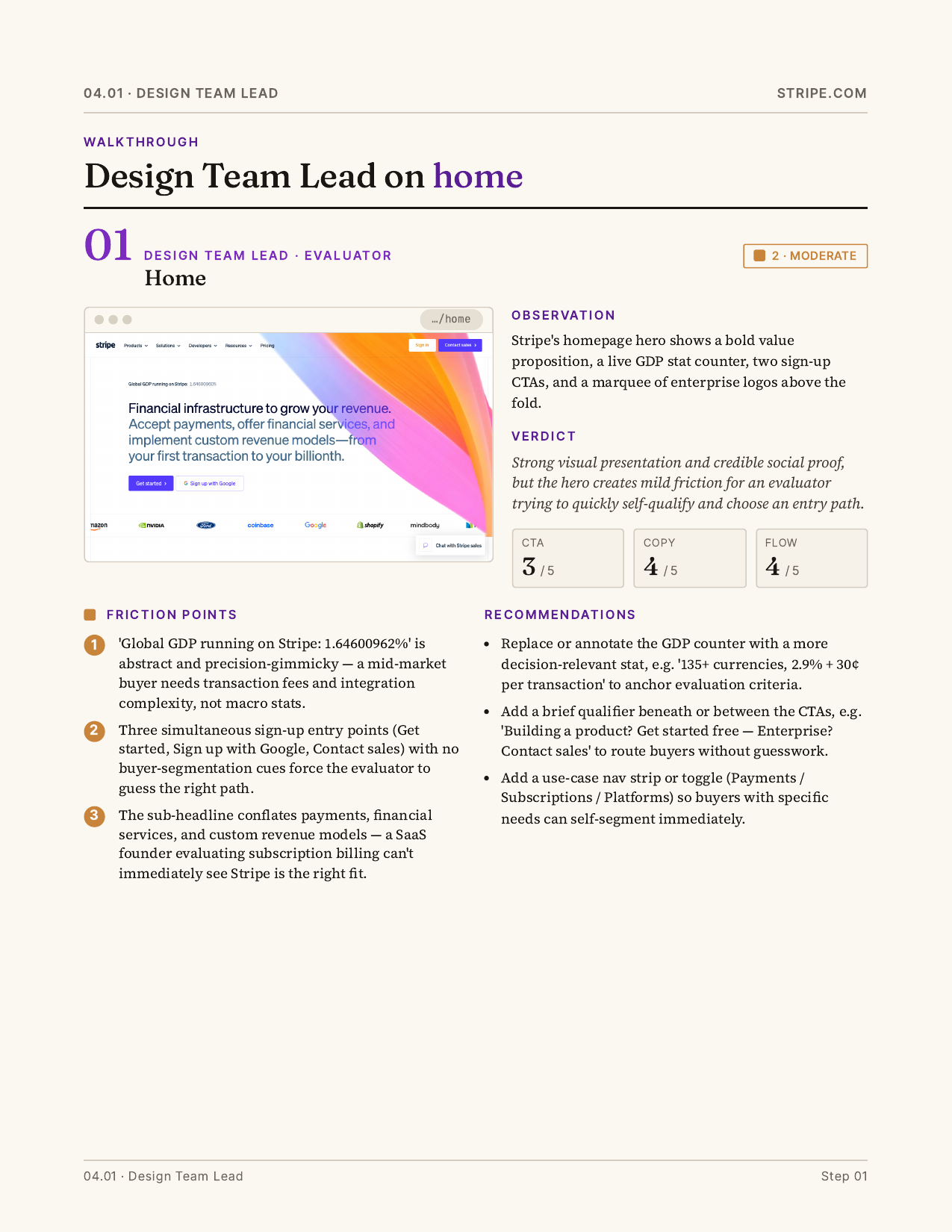
Hard-won bits
Image stripping — pattern from an earlier project
Screenshot bloat is the first cost wall you hit on a multi-step agent loop. I ran into it building QAgent and solved it by walking prior screenshots out of the message history before each new turn — text reasoning stays, images don't. Reasonable UX was built on top of that lesson: stripping was wired in the first commit, not added later under budget pressure. Worth flagging because the advisor pattern adds its own tokens — without image stripping as the floor, layering Opus on top wouldn't pencil out.
JPEG quality tiers
40% quality for per-step screenshots, 60% for full-page below-fold crops. Tuned until legibility broke, then backed off one step. The agent doesn't need print-quality images to reason about layout; spending bytes on crispness it won't use is money on the floor.
The nav:Label dispatch convention
The prompt instructs Claude to emit "target": "nav:Pricing" for
navigation links instead of CSS selectors. Dispatch code translates that to
get_by_role("link", name="Pricing"). Brittle selectors are a known
failure mode of AI-driven browser testing — classes change, IDs get regenerated,
your agent breaks weekly. A semantic handle sidesteps that entirely, and it's the
kind of thing the executor would not have arrived at on its own.
Persona threading
Step one infers the evaluator persona from the first screenshot. Every subsequent step is prompted as that persona. The result is an internally coherent critique rather than a committee of disagreeing reviewers averaged into incoherence. The site tells you who its reader is; the agent just listens.
Pre-ship data-flow audit
Before publishing, I mapped the full data flow from LLM-extracted strings to HTML
output. Found: Claude might extract <script> tags or event
handlers from a malicious audit target verbatim into friction points or
observations. When the report HTML is opened — including when shared with a founder
— the injected markup executes. Stored XSS in the primary deliverable. Fixed with
html.escape() wrapping at all 7 injection points in
agent_core.py. Caught because the audit was part of the pre-public
checklist, not triggered by an incident.
What I'd tell another builder
The advisor pattern isn't just cost optimization. It's a concrete shape for "spec-first, verification-loop" development. You write a specification by picking which model does what and what escalation looks like. The executor model then does the cheap iteration; the advisor sees only the moments where the spec is ambiguous. If you find yourself wanting a bigger model everywhere, that's usually a sign your spec isn't crisp — not that your executor is too dumb.
"Cost down ~4× ($8 Opus → ~$2 Sonnet per 20-URL eval run). The swap regressed pass rate to 5/20... Batch 33 recalibrated labels for Sonnet's actual scoring behavior, restoring 19/20."